











- Qwen 與 Llama 的區別
- 量化介紹
- 省流
DeepSeek 開源的大模型,有些小伙伴在本地部署下載 DeepSeek 模型時會看到 Qwen 與 Llama 蒸餾模型,以及 Q2、Q3、Q4、Q5、Q8 等的代號,不知道如何選擇版本。例如教過大家的👉 超簡單!3 步部署國產 AI 神器「DeepSeek」到你的電腦。又或者通過 LM Studio 本地部署模型工具里面搜索到的 DeepSeek 模型有很多版本。
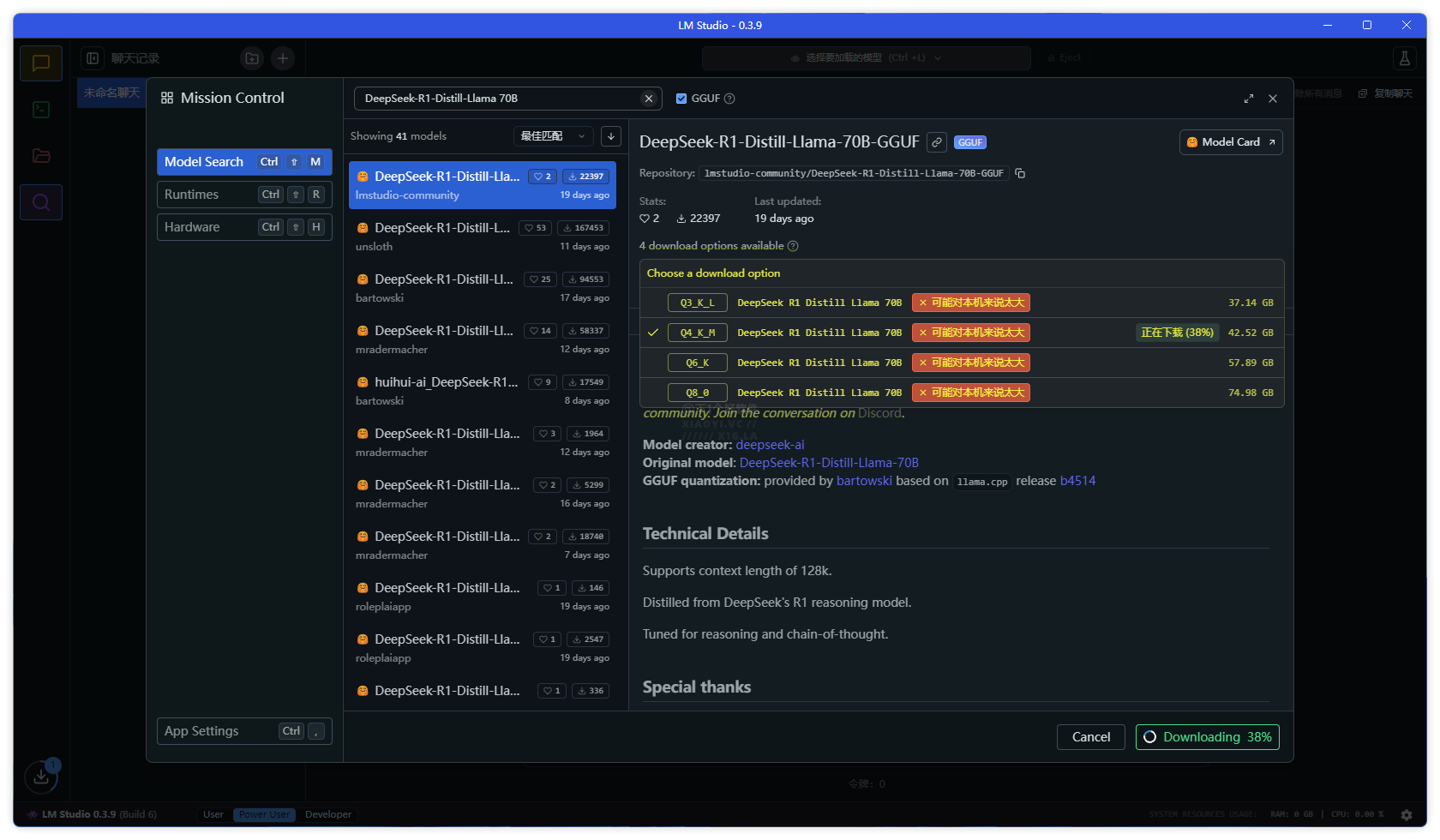
本文小羿給大家介紹 Qwen 與 Llama 區別,以及量化介紹,讓你根據環境需求、硬件要求、是否需要更快的推理速度還是更高的精度,來選擇相關的模型版本。
Qwen (通義千問)
- 開發者:阿里巴巴達摩院
- 架構:基于 Transformer,支持更長上下文窗口
- 訓練數據:側重中文語料,兼顧多語言
- 應用場景:中文 NLP 任務優化
Llama (Meta)
- 開發者:Meta (Facebook)
- 架構:基于 Transformer,優化稀疏注意力機制
- 訓練數據:以英文為主,涵蓋部分多語言數據
- 應用場景:通用任務,適配英文環境更好
Q2、Q3、Q4、Q5、Q8 的代號屬于模型量化技術的標識符,主要取決于量化工具(如 GGUF 格式)。量化旨在降低模型存儲和計算成本,常見規則如下:
Q2_K
- 位寬:2-bit
- 精度損失:高
- 內存占用:極低
- 推理速度:極快
Q3_K_M
- 位寬:3-bit
- 精度損失:中
- 內存占用:低
- 推理速度:快
Q4_K_S
- 位寬:4-bit
- 精度損失:低
- 內存占用:中等
- 推理速度:中等
Q5_K_M
- 位寬:5-bit
- 精度損失:極低
- 內存占用:較高
- 推理速度:較慢
Q8_0
- 位寬:8-bit
- 精度損失:可忽略
- 內存占用:高
- 推理速度:慢
中文處理優先選擇 Qwen 版本,量化參數根據自己的需求和硬件來選(本地部署「DeepSeek」模型硬件配置要求),例如低配置電腦,優先選擇 Q3_K_M 或者 Q4_K_S,也可根據推理速度需求來選一個平衡的參數模型。富哥請隨意。
電腦跑不動本地 DeepSeek 模型,可以看這里:🔥滿血版 DeepSeek 免費 / 限免 API 匯總!持續更新
👉?DeepSeek 專題:DeepSeek 部署教程 / 免費 API 服務 / 入門指南
 魯ICP備2020050029號-1
魯ICP備2020050029號-1 魯ICP備2020050029號-1
魯ICP備2020050029號-1