











本倉庫是對 的重構/更新版本, 是 Stability AI 最初開發的音頻/音樂生成模型開源代碼。
- https://github.com/Stability-AI/stable-audio-tools
本倉庫包含以下額外功能:
- ?? 重構了 的代碼,提高了可讀性和易用性。
- ?? 提供了用于評估和使用自己訓練模型的實用腳本。
- ?? 提供了如何訓練 等模型的說明。
- ?? 為使用 提供了詳細文檔和便捷腳本。
Stability AI 現已開源 Stable Audio 的預訓練模型。
- 官方發布:Introducing Stable Audio Open
如果您對如何使用 Stable Audio Open 感興趣,請參閱以下文檔以獲取詳細說明。
- ?? Stable Audio Open 1.0 文檔
- ?? 現在您可以使用通過 YAML 文件提供的提示輸入進行多 GPU/節點生成。 請參見此處的示例 -> generate_conditions.yaml。
- PyTorch 2.0 或更高版本,以支持 Flash Attention
- 本倉庫的開發在 Python 3.8.10 或更高版本中進行
要運行訓練腳本或推理代碼,您需要克隆此倉庫,導航到根目錄,然后執行以下 命令:
為簡化訓練環境的設置,我建議使用 或 等容器系統,而不是在每臺 GPU 機器上安裝依賴項。以下是創建 Docker 和 Singularity 容器的步驟。
所有示例腳本都存儲在 container 文件夾中。
請確保事先安裝了 Docker 和 Singularity。
運行上述腳本后,應在工作目錄中創建 。
提供了一個基本的 Gradio 界面來測試訓練好的模型。
例如,要為 模型創建界面,一旦您在 Hugging Face 上接受了模型條款,您可以運行:
如果您需要關于 的更詳細說明,我建議參考 文檔中的 Gradio 界面 部分。
腳本接受以下命令行參數:
- PRETRAINED_NAME(可選)
- Hugging Face Hub 上的模型名稱(例如 )
- 將優先選擇倉庫中的 而非
- 指定此參數時,將忽略 和 。
- MODEL_CONFIG(可選)
- 本地模型的模型配置文件路徑
- CKPT_PATH(可選)
- 本地模型的未包裝模型檢查點文件路徑
- PRETRANSFORM_CKPT_PATH(可選)
- 未包裝的預轉換檢查點路徑。這將替換模型中的預轉換。
- USERNAME / PASSWORD(可選)
- 用于設置 Gradio 演示的登錄信息
- (可選)
- 是否使用半精度
- TMP_DIR(可選)
- 保存輸出文件的臨時目錄
訓練代碼還需要一個 Weights & Biases 賬戶來記錄訓練輸出和演示。創建賬戶并使用以下命令登錄:
或者您也可以通過環境變量 傳遞 API 密鑰。 (登錄賬戶后,您可以從 https://wandb.ai/authorize 獲取 API 密鑰。)
當您想使用 Docker 或 Singularity 等容器執行代碼時,這種方法很方便。
在開始訓練之前,您需要準備以下兩個配置文件。
- 模型配置文件
- 數據集配置文件
有關這些文件的更多信息,請參閱下面的配置部分。
要開始訓練,請在倉庫根目錄中運行 腳本:
參數將設置您的 Weights and Biases 運行的項目名稱。
微調涉及從預訓練檢查點恢復訓練運行。
- 要從包裝的檢查點恢復訓練,您可以使用 標志將檢查點路徑 (.ckpt) 傳遞給 。
- 要從預訓練的未包裝模型開始全新訓練,您可以使用 標志將未包裝的檢查點路徑 (.ckpt) 傳遞給 。
使用 PyTorch Lightning 來實現多 GPU 和多節點訓練。
當模型正在訓練時,它被包裝在一個"訓練包裝器"中,這是一個包含所有僅用于訓練的相關對象的 。這包括自動編碼器的判別器、模型的 EMA 副本以及所有優化器狀態等內容。
訓練期間創建的檢查點文件包括這個訓練包裝器,這大大增加了檢查點文件的大小。
接收一個包裝的模型檢查點,并保存一個僅包含模型本身的新檢查點文件。
可以從存儲庫根目錄運行以下命令:
未包裝的模型檢查點是以下情況所必需的:
- 推理腳本
- 將模型用作另一個模型的預轉換(例如,將自動編碼器模型用于潛在擴散)
- 使用修改后的配置對預訓練模型進行微調(即部分初始化)
的訓練和推理代碼基于 JSON 配置文件,這些文件定義了模型超參數、訓練設置和有關訓練數據集的信息。
模型配置文件定義了加載模型進行訓練或推理所需的所有信息。它還包含微調模型或從頭開始訓練所需的訓練配置。
模型配置的頂層定義了以下屬性:
-
- 正在定義的模型類型,目前僅限于 之一。
-
- 訓練期間提供給模型的音頻長度,以樣本為單位。對于擴散模型,這也是推理時使用的原始音頻樣本長度。
-
- 訓練期間提供給模型的音頻采樣率,以及推理期間生成的音頻采樣率,單位為 Hz。
-
- 訓練期間提供給模型的音頻通道數,以及推理期間生成的音頻通道數。默認為 2。單聲道設置為 1。
-
- 正在定義的模型的具體配置,根據 而變化。
-
- 模型的訓練配置,根據 而變化。提供訓練參數以及演示。
目前支持兩種數據源:本地音頻文件目錄和存儲在 Amazon S3 中的 WebDataset 數據集。更多信息可以在數據集配置文檔中找到。
的其他可選標志包括:
-
- 存儲庫根目錄中 defaults.ini 文件的路徑,如果從存儲庫根目錄以外的目錄運行 ,則需要此標志。
-
- 用于各種模型類型,如潛在擴散模型,以加載預訓練的自動編碼器。需要未包裝的模型檢查點。
-
- 保存模型檢查點的目錄。
-
- 保存檢查點之間的步數。
- 默認值:10000
-
- 訓練期間每個 GPU 的樣本數。應設置為 GPU VRAM 所允許的最大值。
- 默認值:8
-
- 每個節點用于訓練的 GPU 數量。
- 默認值:1
-
- 用于訓練的 GPU 節點數量。
- 默認值:1
-
- 啟用并設置梯度批累積的批次數。在較小的 GPU 上訓練時,用于增加有效批量大小。
-
- 分布式訓練的多 GPU 策略。設置為 將啟用 DeepSpeed ZeRO Stage 2。
- 默認值:如果 > 1,則為 ,否則為 None
-
- 訓練期間使用的浮點精度。
- 默認值:16
-
- 數據加載器使用的 CPU 工作進程數。
-
- PyTorch 的 RNG 種子,有助于確定性訓練。
要使用 CLAP 編碼器進行音樂生成的條件控制,您必須準備 CLAP 的預訓練檢查點文件。
- 從 LAION CLAP 存儲庫 下載使用音樂數據集訓練的預訓練 CLAP 檢查點()。
- 將檢查點文件存儲到您選擇的目錄中。
- 按如下方式編輯 Stable Audio 2.0 的 文件
= stable_audio_2_0.json =
由于 Stable Audio 使用文本提示作為音樂生成的條件,因此除了音頻數據之外,您還必須準備它們作為元數據。
在本地環境中使用數據集時,我建議使用以下 JSON 格式的元數據。
- 您可以在 JSON 文件中包含任何信息作為元數據,但必須始終包含名為 的文本數據,這是 Stable Audio 訓練所需的。 = music_2.json =
- 元數據文件必須與相應的音頻文件放在同一目錄下。文件名也必須相同。
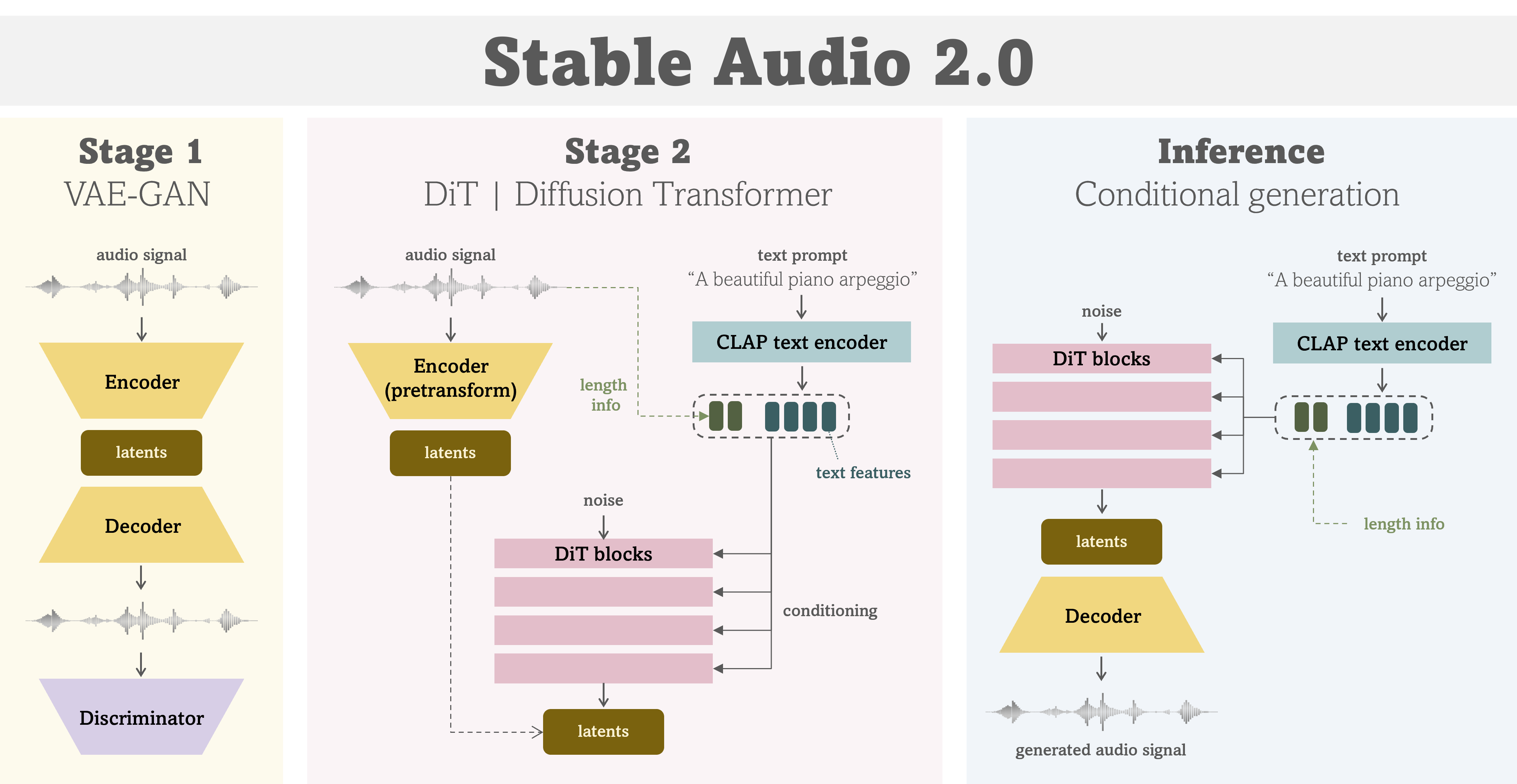
作為Stable Audio 2.0的第一階段,你將訓練一個VAE-GAN,這是一個音頻信號的壓縮模型。
VAE-GAN的模型配置文件位于configs目錄中。關于數據集配置,請根據你自己的數據集準備相應的數據集配置文件。
準備好配置文件后,你可以這樣執行訓練任務:
如解包模型部分所述, 完成VAE訓練后, 你需要解包模型檢查點以用于下一階段的訓練。
完成VAE訓練后,你可能想要測試和評估訓練模型的重構質量。
我支持使用對目錄中的音頻文件進行重構, 你可以使用重構后的音頻進行評估。
作為Stable Audio 2.0的第二階段,你將訓練一個DiT,這是一個潛在域中的生成模型。
在這一部分之前,請確保
- 你已滿足所有先決條件
- 你已經訓練了VAE模型并創建了解包后的檢查點文件(參見VAE部分)
現在,你可以按如下方式訓練DiT模型:
 魯ICP備2020050029號-1
魯ICP備2020050029號-1 魯ICP備2020050029號-1
魯ICP備2020050029號-1